Explore Our Cutting-Edge Research
in AI Optimization
At NetsPresso, we’re advancing the frontier of generative AI model optimization. Discover how our innovative research is transforming the future of efficient and scalable AI systems.
BK-SDM: Efficient Text-to-Image Generation with Compressed Stable Diffusion
The NetsPresso team introduces BK-SDM, a lightweight version of Stable Diffusion optimized for edge devices. By removing redundant blocks and applying knowledge distillation, we significantly reduced the model size and computation cost. Despite its compact size, BK-SDM retains the original model’s ability to generate high-quality images from text prompts. Our experiments show over 30% faster inference and 50% fewer parameters on devices like NVIDIA Jetson and iPhone 14.

Try It on GitHub
Test the Lightweight Model on GitHub
Run the Demo
Demo the Model on Hugging Face
ST-LLaMA: Accelerating Large Language Models through Depth Pruning
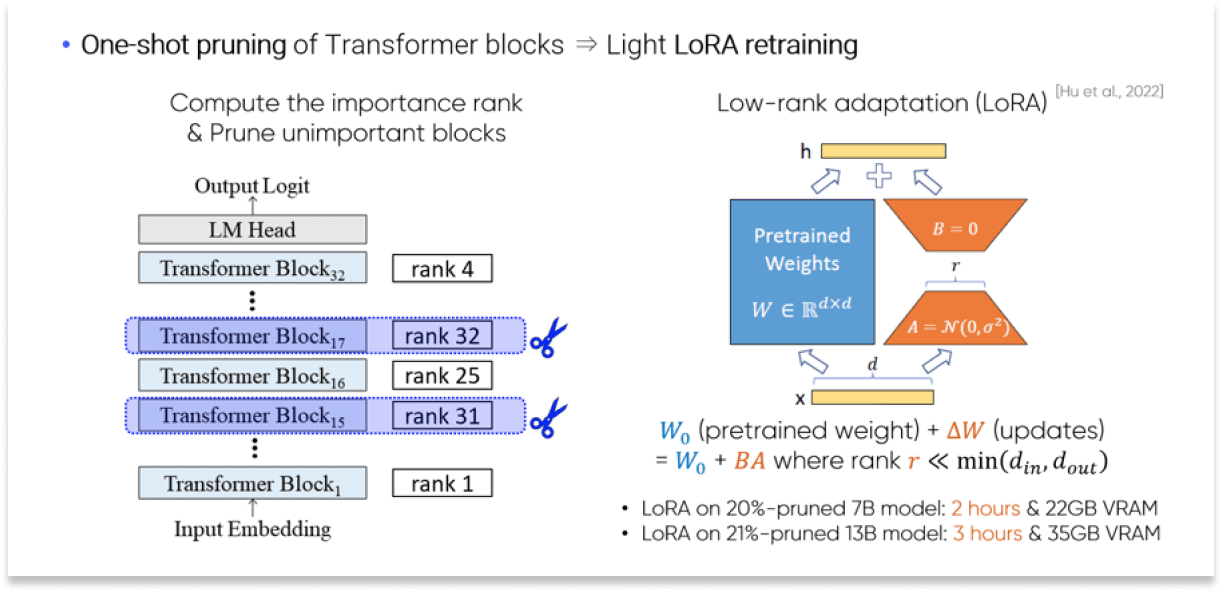
The NetsPresso team presents ST-LLaMA, a depth-pruned variant of LLaMA designed to reduce latency and memory usage in large language models. Unlike width pruning, which often underperforms with small batch sizes, our approach removes full Transformer blocks to enable efficient inference under resource-constrained conditions. Using structured pruning and LoRA-based retraining, we maintain high generation quality while accelerating output by 10–30%. Benchmarks on an RTX3090 show improved speed and throughput, demonstrating the effectiveness of our method. ST-LLaMA offers a practical path to running LLMs more efficiently without compromising performance.
Try It on GitHub
Test the Lightweight Model on GitHub
Run the Demo
Demo the Model on Hugging Face

